Многие языки высокого уровня позволяют программисту разрабатывать алгоритм так, как если бы необходимые данные хранились в прямоугольной структуре, называемой однородным массивом, где термин «однородный» означает, что все элементы массива принадлежат одному типу. В этом разделе мы изучим, как же на самом деле организованы такие массивы, и как транслятор преобразует массив, найденный в исходной программе, в термины ячеек памяти и адресов.
Представьте, что алгоритм для обработки суточных замеров температуры написан на языке высокого уровня. Программисту удобно представлять эти показания в виде одномерного массива с названием Readings, ссылки на элементы которого зависят от их положения в списке. Тогда к первому показателю можно обращаться как к Readings[l], ко второму — как к Readings[2] и т. д. (В языках программирования С, C++, С# и Java эти обращения будут выглядеть как Readings [0] и Readings [1], но нам удобнее нумеровать элементы массива, начиная с единицы. Это преобразование выполняется однозначно. В языках программирования С, С++ и Java индексы массивов начинаются с 0, а не с 1. Поэтому элемент в первой строке и четвертом столбце массива с именем Array будет обозначаться как Array[0][3]. В таком случае, какой адресный полином необходимо применять транслятору для преобразования запросов в форме Array[i][j] в адреса памяти?
Переход от этого одномерного массива к фактической организации данных в памяти машины очень прост, так как данные могут храниться в 24 последовательных ячейках памяти в том же порядке, в каком видит элементы массива программист. Зная адрес первой ячейки последовательности, транслятор может преобразовывать такие ссылки, как Readings [4], в соответствующие термины памяти. Он просто вычитает единицу из индекса нужного элемента и прибавляет результат к адресу ячейки памяти, содержащей первое значение температуры. Если первый показатель находится по адресу х (рис. 1), четвертый будет найден по адресу х + (4 - 1).
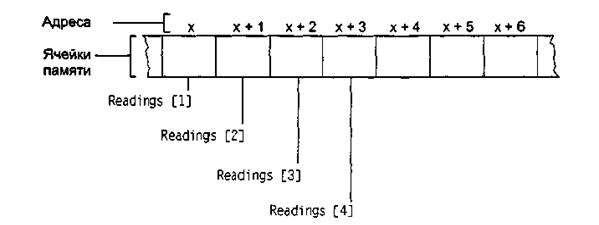
Рисунок 1 – Массив элементов Readings, записанный в памяти. начиная с адреса х
Теперь представим, что программист планирует написать программу для обработки продаж отдела сбыта компании за неделю. Эти данные можно представить в виде таблицы, где в левом столбце перечислены имена сотрудников отдела, а в верхней строке — дни недели. Следовательно, программисту удобно представить данные в программе как двумерный массив, каждая строка которого обозначает продажи, осуществленные определенным сотрудником, а значения в столбце — это все продажи, сделанные в один день.
Память машины организована не как таблица, а скорее как цепочка ячеек с последовательными адресами. Поэтому требуемую прямоугольную структуру массива придется имитировать. Чтобы сделать это, представим, что массив статичен, то есть его размер не изменяется по мере внесения изменений в данные. Теперь подсчитаем объем памяти, необходимый для всего массива, и зарезервируем непрерывный блок ячеек памяти полученного размера. Начиная с первой ячейки этого блока, последовательно в каждую ячейку записываем значения из первой строки массива; после первой строки таким же образом записываем вторую, третью и т. д. (рис. 3). Такая система хранения называется построчной (row major order), в отличие от постолбцовой (column major order), где один за другим записываются все столбцы массива.
Давайте теперь подумаем, как найти ячейку памяти, содержащую значение на пересечении третьей строки и четвертого столбца массива, если данные организованы подобным образом. Представим себя на месте первой ячейки зарезервированного блока машинной памяти. Начиная с этого положения, можно найти данные первой строки массива, за ней второй, третьей и т. д. Для получения данных третьей строки необходимо пройти первую и вторую строки. Так как в каждой строке содержится по пять элементов (по одному на каждый день с понедельника по пятницу), мы пройдем 10 ячеек и окажемся на первом элементе третьей строки. С этого места нам придется пропустить еще три элемента, чтобы попасть на четвертый столбец массива. Итого, для достижения элемента из третьей строки и четвертого столбца мы проходим 13 элементов от начала блока.
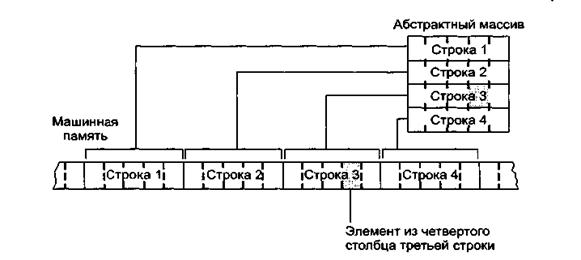
Рисунок 2 – Двумерный массив из четырех строк и пяти столбцов, записанный построчно
Упомянутые ранее расчеты можно обобщить на случай процесса, при помощи которого транслятор преобразует ссылки в терминах положения в строке и столбце в фактические адреса памяти. В частности, пусть с представляет количество столбцов в массиве (то есть количество элементов в каждой строке), тогда адрес элемента на пересечении i-й строки j-го столбца:
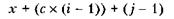
где х — адрес ячейки, содержащей элемент на пересечении первой строки и первого столбца. Таким образом, для достижения i-й строки нам нужно пропустить i - 1 строк, в каждой из которых с элементов, а затем для достижения j-гo элемента в этой строке — еще j — 1 элементов. В предыдущем примере с = 5, i = 3 и j = 4, поэтому, если первый элемент массива находится по адресу х, элемент из третьей строки и четвертого столбца будет находиться по адресу

(Выражение (с х (i - 1)) + (j - 1) иногда называют адресным полиномом (address polynomial)).
Зная этот алгоритм, можно написать приложение для преобразования запросов в виде номеров строк и столбцов в адреса внутри блока памяти, содержащего массив. Например, транслятор при помощи этой техники преобразует запросы вида Sales[2.4] в фактические адреса памяти. А программист тем временем может представлять данные в табличной форме (абстрактная структура), даже если на самом деле они хранятся в одной строке (фактическая структура).
Списки
Список — это набор записей, выстроенных в определенной последовательности. Примерами могут служить список учащихся класса, список дел на день или словарь. Менее очевидные примеры — это предложения, которые можно рассматривать как последовательности слов, и слова, состоящие из последовательностей букв. В отличие от однородных массивов, имеющих статическую природу1, списки могут быть как статическими, так и динамическими. В этом разделе мы узнаем об особенностях, возникающих при реализации динамического списка в сравнении со статическим.
Непрерывные списки. Рассмотрим способы хранения списков имен в оперативной памяти компьютера. Одна из стратегий — это запись всего списка в один блок ячеек памяти с последовательными адресами. Предположив, что в каждом имени не более восьми букв, мы можем разделить большой блок ячеек на подблоки, содержащие по восемь ячеек. В каждом подблоке можно хранить имя, записав его в кодах ASCII и используя для каждой буквы одну ячейку. Если длины имени не хватает для заполнения всех ячеек в выделенном для него подблоке, оставшиеся ячейки можно заполнить кодом ASCII для пробела. Этот подход требует 80 последовательных ячеек памяти для хранения списка из 10 имен.
Реализация непрерывных списков.Примитивы для конструирования и манипуляции массивами, предлагаемые в большинстве языков программирования высокого уровня, являются также удобными инструментами для создания и работы с непрерывными списками. Если все элементы списка принадлежат одному примитивному типу данных, тогда список — это не что иное, как одномерный однородный массив. Рассмотренный в этом разделе список из десяти имен, каждое из которых не длиннее восьми символов, представляет более сложный пример. В таком случае программист может создать непрерывный список в виде двумерного массива символов, состоящего из десяти строк и восьми столбцов, размещение которого в непрерывном блоке оперативной памяти показано на рис. 7.4 (мы предполагаем, что массив хранится построчно).
Во многих языках программирования высокого уровня есть возможности для подобной реализации списков. Например, в описанном ранее двумерном массиве символов MemberList выражение MemberList[3,5] будет относиться к одному символу на пересечении третьей строки и пятого столбца, но в некоторых языках выражение MemberList[3] используется для обращения ко всей третьей строке, являющейся третьей записью в списке.
Важно заметить, что весь список в соответствии с описанной выше системой хранения располагается в одном большом блоке памяти (рис. 3), и элементы списка записаны один за другим в последовательные ячейки памяти. Такая организация данных называется непрерывным списком (contiguous list).
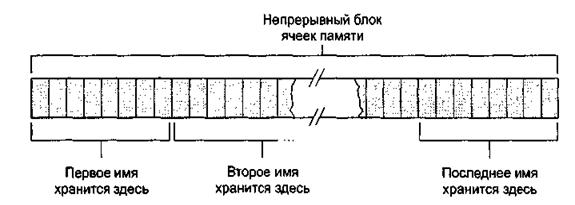
Рисунок 3 – Имена, хранящиеся в памяти в виде непрерывного списка
Непрерывный список — это удобная структура хранения для реализации статических списков, но у него есть недостатки, делающие его не слишком подходящим для динамических случаев. Предположим, например, что нам потребовалось удалить имя из непрерывного списка. Если имя находится в начале списка, и мы хотим сохранить существующий порядок в списке (например, алфавитный), придется переместить все имена, стоящие за удаленным, ближе к началу списка, чтобы закрыть отверстие, появившееся при удалении. Более серьезная проблема появляется с необходимостью добавления имен, поскольку может потребоваться переместить весь список для освобождения непрерывного блока ячеек, достаточного для расширения списка.
Связные списки.Проблем, возникающих при работе с динамическими списками, можно избежать, разрешив хранение отдельных имен в различных областях памяти, а не вместе, в одном большом непрерывном блоке. Чтобы разобраться в этом, вернемся к нашему примеру хранения списка имен, каждое из которых не длиннее восьми символов. Можно хранить каждое имя в блоке из девяти смежных ячеек памяти. Первые восемь необходимы для записи самого имени, а последняя ячейка будет использоваться как указатель на следующее имя в списке. Следуя этому принципу, список можно раскидать по небольшим блокам, каждый из 9 ячеек, которые связаны между собой указателями. Из-за такой системы связей подобная организация называется связным списком (linked list).
Для того чтобы определить начало связного списка, отдельно определяется еще один указатель, в котором хранится адрес первой записи. Так как этот указатель указывает на начало, или голову списка, он называется указателем головы (head pointer).
Для определения конца связного списка мы используем пустой указатель (NIL pointer), который является просто определенного вида набором битов и находится в последней записи, указывая, что за ним в списке более нет элементов. Например, если мы условимся никогда не хранить элементы списка по адресу 0, значение 0 никогда не будет являться разрешенным значением указателя, и поэтому его можно использовать как пустой указатель.
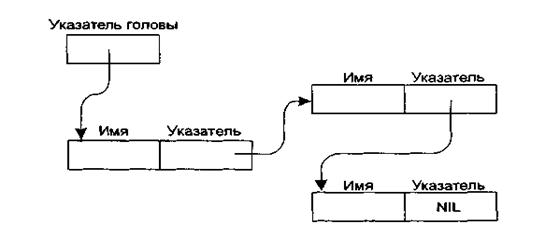
Рисунок 4 – Структура связного списка
На диаграмме (рис. 4) отдельные блоки памяти, в которых хранятся элементы связного списка, представлены в виде прямоугольников. Строение каждого прямоугольника обозначено надписями. Указатели представлены стрелками, идущими от самого указателя к адресу, на который тот указывает. Для прохождения списка нужно последовать указателю головы — так мы найдем первую запись.
Далее необходимо следовать указателям, хранящимся в записях, и по ним переходить от элемента к элементу до достижения пустого (NIL) указателя.
Теперь вернемся к вопросу удаления и добавления элементов в список. Нам нужно увидеть, как использование указателей устраняет необходимость перемещения имен, возникающую при хранении списка в одном связном блоке. Для начала заметим, что удалить имя можно, изменив один указатель. Это означает, что указатель, который ранее указывал на удаленное имя, изменяется и указывает теперь на имя, следующее за удаленным (рис. 5). И тогда при прохождении списка удаленное имя пропускается, поскольку не является более элементом цепочки.
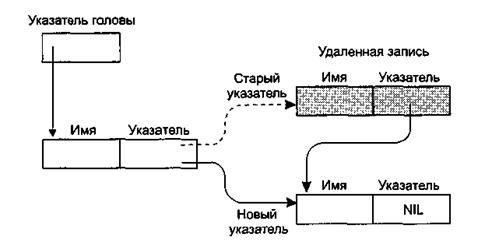
Рисунок 5 – Удаление записи из связного списка
Добавление нового имени ненамного сложнее. Сначала находим неиспользуемый блок из девяти ячеек памяти, записываем новое имя в первые восемь ячеек, а в девятую записываем адрес имени, которое должно следовать в списке за новым. Затем изменяем указатель, связанный с именем, которое должно предшествовать новому имени в списке так, чтобы он указывал на этот новый блок (рис. 6). После этого новую запись можно будет найти на нужном месте при прохождении списка.
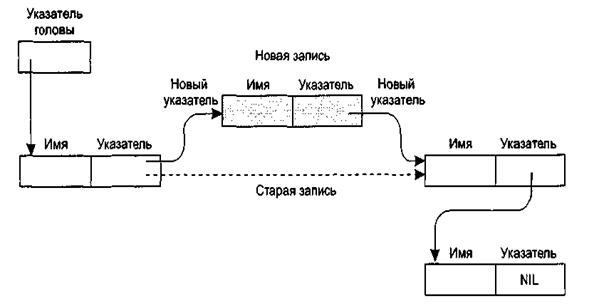
Рисунок 6 – Добавление записи в связный список
Поддержка абстрактного списка. Во время написания программы программисту часто приходится решать, реализовывать ли список в виде непрерывной или связной структуры. После того как решение принято и список создан, программист должен оставить эти вопросы и сконцентрироваться на прочих деталях. Вкратце, программа должна быть сконструирована так, чтобы к списку можно было обратиться как к абстрактному инструменту из любой части программы.
Возьмем задачу разработки приложения для обработки и регистрации списков студентов, предназначенную для секретаря университета. Программист, занимающийся этой задачей, может создать для каждой группы отдельные списки имен студентов, отсортированные в алфавитном порядке. Как только списки созданы, внимание программиста должно быть обращено на общие концепции задачи, и он не должен постоянно отвлекаться на такие детали, как смещение элементов в непрерывном списке или перемещение указателей в связном списке.
С этой Цель лекциию программист может написать набор процедур, выполняющих такие действия, как добавление новой записи, удаление старой записи, поиск записи или печать списка, а затем использовать эти процедуры в приложении для управления списками регистрационной системы. Например, чтобы поместить студента J. W. Brown в группу Physics 208, программист может написать оператор такого типа:
Insert ("Brown. J.W.". Physics208)
и передать ответственность за выполнение действий по вставке элемента процедуре Insert. Таким же образом программист будет разрабатывать другие части программы, не сосредотачиваясь на технических подробностях добавления элементов.
Примером такого подхода может служить процедура PrintList (листинг 1), предназначенная для печати связного списка имен. На первую запись списка указывает указатель головы; каждая запись состоит из двух частей: имени и указателя на следующую запись. После того как такая процедура написана, ее можно использовать как абстрактный инструмент для печати списков и не думать о шагах, которые фактически предпринимаются для выполнения этой операции. Например, чтобы распечатать список группы Economics 301, программист напишет: PrintList CEconomics301) Листинг 7.1. Процедура печати связного списка
procedure PrintList (List)
CurrentPointer <- указатель головы списка List.
while (CurrentPointer не NIL) do
(Печать имени из элемента списка, на который указывает CurrentPointer: Считывание указателя из элемента списка List, на который указывает CurrentPointer. и присваивание этого значения CurrentPointer.)
Контрольные вопросы
1. Что такое массив в концептуальном и физическом представлении?
2. Как осуществляется доступ к элементам массива?
3. Какая опасность подстерегает программиста при работе с массивами в языке программирования Си++?
4. Что такое список в концептуальном и физическом представлении?
5. Какие виды списков бывают. Покажите на примере их целесообразность применения.
Лекция № 24 Стеки














