15 апреля 2014 в 10:04
Lock-free структуры данных. Очередной трактат

Как вы, наверное, догадались, эта статья посвящена lock-free очередям.
Очереди бывают разные. Они могут различаться по числу писателей (producer) и читателей (consumer) – single/multi producer — single/multi consumer, 4 варианта, — они могут быть ограниченными (bounded, на основе предраспределенного буфера) и неограниченными, на основе списка (unbounded), с поддержкой приоритетов или без, lock-free, wait-free или lock-based, со строгим соблюдением FIFO (fair) и не очень (unfair) и т.д. Подробно типы очередей описаны в этой и этой статьях Дмитрия Вьюкова. Чем более специализированы требования к очереди, тем, как правило, более эффективным оказывается её алгоритм. В данной статье я рассмотрю самый общий вариант очередей — multi-producer/multi-consumer unbounded concurrent queue без поддержки приоритетов.
первой статьи цикла
struct Node {
Node * m_pNext ;
};
class queue {
Node * m_pHead ;
Node * m_pTail ;
public:
queue(): m_pHead( NULL ), m_pTail( NULL ) {}
void enqueue( Node * p )
{
p->m_pNext = nullptr;
if ( m_pTail )
m_pTail->m_pNext = p;
else
m_pHead = p ;
m_pTail = p ;
}
Node * dequeue()
{
if ( !m_pHead ) return nullptr ;
Node * p = m_pHead ;
m_pHead = p->m_pNext ;
if ( !m_pHead )
m_pTail = nullptr ;
return p ;
}
};
Не ищите, здесь нет конкурентности, — это просто иллюстрация, насколько простой выбран предмет для разговора. В статье мы увидим, что бывает с простыми алгоритмами, если их начинают приспосабливать к конкурентной среде.
UPD: спасибо xnike, кто первым нашел здесь ошибку!
Классическим (1996 год) алгоритмом lock-free очереди считается алгоритм Michael & Scott.
Как всегда, простыня код приводится из библиотеки libcds, если в ней есть реализация рассматриваемого алгоритма, в сокращенном (адаптированном) виде. Полный код — см. класс cds::intrusive::MSQueue. Комментарии вставлены по коду, старался, чтобы они не были очень уж скучными.
bool enqueue( value_type& val )
{
/*
Implementation detail: в моей реализации node_type и value_type -
это не одно и то же и требует приведения из одного в другое
Для простоты можно считать, что node_traits::to_node_ptr -
это просто static_cast<node_type *>( &val )
*/
node_type * pNew = node_traits::to_node_ptr( val ) ;
typename gc::Guard guard; // Защитник, например, Hazard Pointer
// Back-off стратегия (template-аргумент класса)
back_off bkoff;
node_type * t;
// Как всегда в lock-free, долбимся, пока не сделаем нужное дело...
while ( true ) {
/*
Защищаем m_pTail, как как мы далее будем читать его поля
и не хотим попасть в ситуацию чтения из удаленной (delete)
памяти
*/
t = guard.protect( m_pTail, node_to_value() );
node_type * pNext = t->m_pNext.load(
memory_model::memory_order_acquire);
/*
Интересная деталь: алгоритм допускает,
что m_pTail может указывать не на хвост,
и надеется, что следующие вызовы настроят
хвост правильно. Типичный пример многопоточной взаимопомощи
*/
if ( pNext != nullptr ) {
// Упс! Требуется зачистить хвост
//(в прямом смысле) за другим потоком
m_pTail.compare_exchange_weak( t, pNext,
std::memory_order_release, std::memory_order_relaxed);
/*
Нужно начинать все сначала, даже если CAS не удачен
CAS неудачен — значит, m_pTail кто-то
успел поменять после того, как мы его прочитали.
*/
continue ;
}
node_type * tmp = nullptr;
if ( t->m_pNext.compare_exchange_strong( tmp, pNew,
std::memory_order_release,
std::memory_order_relaxed ))
{
// Успешно добавили новый элемент в очередь.
break ;
}
/*
У нас ничего не получилось — CAS не сработал.
Это значит, что кто-то успел влезть перед нами.
Обнаружена конкуренция — дабы не усугублять её,
отступим на очень краткий момент времени —
вызываем функтор back_off
*/
bkoff();
}
/*
Вообще, счетчик элементов — это по желанию...
Как видно, этот счетчик не очень-то и точный —
элемент уже добавлен, а счетчик меняем только сейчас.
Такой счетчик может говорить лишь о
порядке числа элементов, но применять его
как признак пустоты очереди нельзя
*/
++m_ItemCounter ;
/*
Наконец, пытаемся изменить сам хвост m_pTail.
Нас здесь не интересует, получится у нас или нет, — если нет,
за нами почистят, см. 'Упс!' выше и ниже, в dequeue
*/
m_pTail.compare_exchange_strong( t, pNew,
std::memory_order_acq_rel, std::memory_order_relaxed );
/*
Этот алгоритм всегда возвращает true.
Другие, например, bounded queue, могут
вернуть и false, когда очередь полна.
Для единообразия интерфейса enqueue
всегда возвращает признак успеха
*/
return true;
}
value_type * dequeue()
{
node_type * pNext;
back_off bkoff;
// Для dequeue нам нужно 2 Hazard Pointer'а
typename gc::template GuardArray<2> guards;
node_type * h;
// Долбимся, пока не сможем выполнить...
while ( true ) {
// Читаем и защищаем голову m_pHead
h = guards.protect( 0, m_pHead, node_to_value() );
// и следуюий за головой элемент
pNext = guards.protect( 1, h->m_pNext, node_to_value() );
// Проверяем: то, что мы только что прочли,
// осталось связанным?..
if ( m_pHead.load(std::memory_order_relaxed) != h ) {
// нет, - кто-то успел нам все испортить...
// Начинаем сначала
continue;
}
/*
Признак пустоты очереди.
Отметим, что в отличие от хвоста голова всегда
находится на правильном месте
*/
if ( pNext == nullptr )
return nullptr; // очередь пуста
/*
Здесь мы читаем хвост, но защищать его
Hazard Pointer'ом не нужно — нас не интересует содержимое,
на которое он указывает (поля структуры)
*/
node_type * t = m_pTail.load(std::memory_order_acquire);
if ( h == t ) {
/*
Упс! Хвост не на месте: есть голова,
есть следующий за головой элемент,
а хвост указывает на голову.
Требуется помочь нерадивым товарищам...
*/
m_pTail.compare_exchange_strong( t, pNext,
std::memory_order_release, std::memory_order_relaxed);
// После помощи все приходится начинать заново -
// поэтому нам не важен результат CAS
continue;
}
// Самый важный момент — линкуем новую голову
// То есть продвигаемся по списку ниже
if ( m_pHead.compare_exchange_strong( h, pNext,
std::memory_order_release, std::memory_order_relaxed ))
{
// Удалось — завершаем наш бесконечный цикл
break;
}
/*
Не удалось... Значит, кто-то нам помешал.
Чтобы не мешать другим, отвлечемся на мгновение
*/
bkoff() ;
}
// Изменяем не очень-то и полезный счетчик элементов,
// см. коммент в enqueue
--m_ItemCounter;
// Это вызов функтора 'удаление элемента h'
dispose_node( h );
/*
!!! А вот это интересный момент!
Мы возвращаем элемент, следующий за [бывшей] головой
Заметим, что pNext все еще в очереди —
это наша новая голова!
*/
return pNext;
}
Как видим, очередь представлена односвязным списком от головы к хвосту.
Какой в этом алгоритме важный момент? Важный момент — исхитриться управлять двумя указателями — на хвост и на голову — с помощью обычного (не двойного!) CAS. Это достигается за счет, во-первых, того, что очередь никогда не пуста, — посмотрите внимательно на код, есть там где-нибудь проверки головы/хвоста на nullptr?.. Не найдете. Для обеспечения физической (но не логической) непустоты в конструкторе очереди в неё добавляется один ложный (dummy) элемент, который и является головой и хвостом. А следствие из этого такое: при извлечении (dequeue) возвращается элемент, который становится новым dummy-элементом (новой головой), а прежний dummy-элемент (бывшая голова) удаляется:

Этот момент следует учитывать при конструировании интрузивной очереди — возвращаемый указатель все ещё часть очереди и его можно будет удалить только при
следующем dequeue.
Во-вторых, алгоритм явно допускает, что хвост может указывать не на последний элемент. При всяком чтении хвоста мы проверяем, есть ли у него следующий элемент m_pNext. Если этот указатель не nullptr — хвост не на месте, требуется его продвинуть. Здесь есть ещё один подводный камень: может случиться так, что хвост будет указывать на элемент
перед головой (пересечение головы и хвоста). Чтобы избежать этого, мы в методе dequeue неявно проверяем m_pTail->m_pNext: мы прочли голову, следующий за головой элемент m_pHead->m_pNext, убедились, что pNext != nullptr, а затем видим, что голова равна хвосту. Следовательно, за хвостом что-то есть, раз есть pNext, и хвост надо продвинуть вперед. Типичный пример взаимопомощи (helping) потоков, который очень распространен в lock-free программировании.
Memory orderingЯ стыдливо спрячу за спойлером такое своё признание: приведенный выше код не является образцом в части расстановки memory ordering атомарных операций. Дело в том, что я не видел подробного с точки зрения C++11 memory ordering анализа алгоритмов сложнее стека Treiber'а. Поэтому в данном коде memory ordering расставлены скорее по интуиции, с небольшим добавлением мозга. Интуиция подкреплена многолетним прогоном тестов, и не только на x86. Вполне допускаю (и даже подозреваю), что существуют более слабые барьеры для этого кода, остаюсь открыт для обсуждения.
В 2000 году была предложена небольшая оптимизация этого алгоритма. Было отмечено, что в алгоритме MSQueue в методе dequeue
на каждой итерации цикла происходит чтение хвоста, что является излишним: хвост нужно читать (чтобы проверить, что он действительно хвост и указывает на последний элемент) только когда произошло успешное обновление головы. Тем самым можно ожидать снижения давления на m_pTail при некоторых типах нагрузки. Эта оптимизация представлена в libcds классом cds::intrusive::MoirQueue.
Baskets queue
Интересная вариация MSQueue была представлена в 2007 году. Довольно известный в lock-free кругах исследователь Nir Shavit со товарищи подошел к оптимизации классической lock-free очереди Майкла и Скотта с другой стороны.
Он представил очередь как набор логических корзин (basket), каждая из которых доступна для добавления нового элемента некоторый краткий интервал времени. Интервал прошел — создается новая корзина.

Каждая корзина — это неупорядоченный набор элементов. Казалось бы, при таком определении нарушается основное свойство очереди — FIFO, то есть очередь становится не совсем очередью (unfair). FIFO соблюдается для корзин, но не для элементов в корзинах. Если интервал доступности корзины для добавления достаточно мал, можно пренебречь неупорядоченностью элементов в ней.
Как определить длительность этого интервала? А его и не надо определять, говорят авторы Baskets Queue. Рассмотрим очередь MSQueue. В операции enqueue при высокой конкуренции, когда CAS изменения хвоста не сработал, то есть там, где в MSQueue вызывается back-off, мы не можем определить, в каком порядке элементы будут добавлены в очередь, так как они добавляются
одновременно. Это и есть логическая корзина. По сути получается, что абстракция логических корзин — это разновидность back-off стратегии.
Я не любитель читать в обзорных статьях километры кода, поэтому код приводить не буду. На примере MSQueue мы уже увидели, что lock-free код очень многословен. Желающих посмотреть реализацию отсылаю к классу cds::intrusive::BasketQueue библиотеки libcds, файл cds/intrusive/basket_queue.h. Я же для пояснения алгоритма позаимствую из работы Nir Shavit & Co ещё одну картинку:

1. Потоки A, B, C желают добавить элементы в очередь. Они видят, что хвост находится на положенном ему месте (а мы помним, что в MSQueue хвост может указывать совсем не на последний элемент в очереди) и пытаются
одновременно изменить его.
2. Поток A вышел победителем — добавил новый элемент. Потоки B и C лузеры — их CAS с хвостом неудачен, поэтому они оба начинают добавлять свои элементы
в корзину, используя ранее прочитанное
старое значение хвоста.
3. Потоку B первым удалось выполнить добавление. В то же самое время поток D также вызывает enqueue и успешно добавляет свой элемент, изменяя хвост.
4. Поток C также успешно завершает добавление. Смотрим, куда он добавил, — в середину очереди! При добавлении он использует старый указатель на хвост, который он прочел при входе к операцию перед выполнением своего неудачного CAS.
Следует отметить, что при таком добавлении вполне может случиться, что элемент будет вставлен
перед головой очереди. Например, элемент перед C на рисунке 4 выше: пока поток C топчется в enqueue, другой поток может уже удалить элемент перед C. Для предотвращения такой ситуации предлагается применить
логическое удаление, то есть сперва пометить удаленные элементы специальным флагом deleted. Так как требуется, чтобы флаг и сам указатель на элемент могли быть прочитаны атомарно, будем хранить этот флаг в младшем бите указателя pNext элемента. Это допустимо, так как в современных системах память выделяется выравненной как минимум по 4 байтам, так что младшие 2 бита указателя всегда будут нулями. Таким образом мы изобрели прием
marked pointers, широко применяющийся в lock-free структурах данных. Этот прием нам ещё не раз встретится в дальнейшем. Применив логическое удаление, то есть выставив младший бит pNext в 1 с помощь CAS, мы исключим возможность вставить элемент перед головой, — вставка осуществляется также CAS'ом, а удаленный элемент содержит 1 в младшем бите указателя, так что CAS будет неудачен (конечно, при вставке мы берем не весь marked pointer, а только его старшие биты, содержащие собственно адрес, младший бит полагаем нулем).
И последнее улучшение, вводимое BasketQueue, касается физического удаления элементов. Было замечено, что изменять голову при каждом успешном вызове dequeue может быть накладно, — там же вызывается CAS, который, как в знаете, довольно тяжелый. Поэтому голову будем менять только когда накопится
несколько логически удаленных элементов (в реализации libcds по умолчанию три). Либо когда очередь становится пустой. Можно сказать, что голова в BasketQueue изменяется прыжками (hops).
Все эти оптимизации призваны улучшить производительность классической lock-free очереди в ситуации высокой конкуренции.
Оптимистический подход

В 2004 году Nir Shavit и Edya Ladan Mozes предложили ещё один подход к оптимизации MSQueue, названный ими
оптимистическим.
WarningЕсли кто заинтересуется оригинальной статьей — будьте внимательны! Существует две одноименные статьи — 2004 года и 2008. В статье 2004 года приводится какой-то зубодробительный (и, похоже, неработоспособный) псевдокод очереди.
В статье 2008 года псевдокод совершено другой, — приятный для глаз и рабочий.
Они заметили, что в алгоритме Майкла и Скотта операция dequeue требует только одного CAS, тогда как enqueue — двух (см. рисунок справа).
Этот второй CAS в enqueue может существенно влиять на производительность даже при малой нагрузке, — CAS в современных процессорах довольно тяжелая операция. Можно ли как-то от него избавиться?..
Рассмотрим, откуда в MSQueue::enqueue взялось два CAS. Первый CAS связывает новый элемент с хвостом — изменяет pTail->pNext. Второй — продвигает сам хвост. Можно поле pNext изменять обычной атомарной записью, а не CAS'ом? Да, если направление нашего односвязного списка было бы другим — не от головы к хвосту, а наоборот, — мы могли бы для задания pNew->pNext использовать атомарный store (pNew->pNext = pTail), а затем CAS'ом менять pTail. Но если мы изменим направление, то как же тогда делать dequeue? Связи pHead->pNext уже не будет, — направление списка поменялось.
Авторы оптимистической очереди предложили использовать
двусвязный список.

Здесь есть одна проблема: эффективного алгоритма двусвязного lock-free списка на CAS ещё не известно. Известны алгоритмы для DCAS (CAS над
двумя различными ячейками памяти), но воплощения DCAS в железе нет. Известен алгоритм эмуляции MCAS (CAS над M несвязанными ячейками памяти) на CAS'ах, но он неэффективен (требует 2M + 1 CAS) и представляет скорее теоретический интерес.
Авторы предложили такое решение: связь в списке от хвоста к голове (next, та связь, которая для очереди
не нужна, но введение этой связи позволяет избавиться от первого CAS в enqueue) будет консистентной всегда. А вот обратная связь — от головы к хвосту, самая важная, prev – может быть и не совсем консистентной, то есть допустимо её нарушение. Если мы обнаружим такое нарушение, мы всегда сможем восстановить правильный список, следуя по next-ссылкам. Как обнаружить такое нарушение? Очень просто: pHead->prev->next != pHead. Если в dequeue обнаруживается это неравенство — запускается вспомогательная процедура fix_list:
void fix_list( node_type * pTail, node_type * pHead )
{
// pTail и pHead уже защищены Hazard Pointer'ами
node_type * pCurNode;
node_type * pCurNodeNext;
typename gc::template GuardArray<2> guards;
pCurNode = pTail;
while ( pCurNode != pHead ) { // Пока не достигнем головы
pCurNodeNext = guards.protect(0, pCurNode->m_pNext, node_to_value() );
if ( pHead != m_pHead.load(std::memory_order_relaxed) )
break;
pCurNodeNext->m_pPrev.store( pCurNode, std::memory_order_release );
guards.assign( 1, node_traits::to_value_ptr( pCurNode = pCurNodeNext ));
}
}
[Взято из класса cds::intrusive::OptimisticQueue библиотеки libcds]
fix_list пробегает по всей очереди от хвоста к голове по заведомо
правильным ссылкам pNext и корректирует pPrev.
Нарушение списка от головы к хвосту (указателей prev) возможно скорее из-за задержек, а не из-за сильной нагрузки. Задержки — это вытеснение потока операционной системой или прерывание. Рассмотрим код OptimisticQueue::enqueue:
bool enqueue( value_type& val )
{
node_type * pNew = node_traits::to_node_ptr( val );
typename gc::template GuardArray<2> guards;
back_off bkoff;
guards.assign( 1, &val );
node_type * pTail = guards.protect( 0, m_pTail, node_to_value());
while( true ) {
// Формируем прямой список — от хвоста к голове
pNew->m_pNext.store( pTail, std::memory_order_release );
// Пытаемся поменять хвост
if ( m_pTail.compare_exchange_strong( pTail, pNew,
std::memory_order_release, std::memory_order_relaxed ))
{
/*
Формируем обратный список — от головы к хвосту.
Здесь ОС нас может прервать (вытеснить).
В результате pTail может быть уже вытолкнут (dequeue) из очереди
(но нам это не страшно, так как pTail у нас защищен
Hazard Pointer'ом и, значит, неудаляем)
*/
pTail->m_pPrev.store( pNew, std::memory_order_release );
break ; // Enqueue done!
}
/*
CAS неудачен — pTail изменился (помним о сигнатуре
CAS в C++11: первый элемент передается по ссылке!)
Защищаем новый pTail Hazard Pointer'ом
*/
guards.assign( 0, node_traits::to_value_ptr( pTail ));
// High contention - отвлечемся
bkoff();
}
return true;
}
Получается, что мы оптимисты: мы строим список pPrev (самый важный для нас), рассчитывая на успех. А если потом обнаружим рассогласование прямого и обратного списка — что ж, придется потратить время на согласование (запуск fix_list).
Итак, что в сухом остатке? И enqueue, и dequeue у нас теперь имеют ровно по одному CAS. Цена — запуск fix_list при обнаружении нарушения списка. Большая это цена или маленькая — скажет эксперимент.
Рабочий код можно найти в файле cds/intrusive.optimistic_queue.h, класс cds::intrusive::OptimisticQueue библиотеки libcds.
Wait-free queue
Для завершения разговора о классической очереди стоит упомянуть об алгоритме wait-free очереди.
Wait-free – самое строгое требование среди прочих. Говорит оно о том, что время выполнения алгоритма должно быть конечно и предсказуемо. На практике wait-free алгоритмы часто заметно (сюрприз!)
уступают по производительности своим менее строгим собратьям — lock-free и obstruction-free, — превосходя их по количеству и сложности кода.
Строение многих wait-free алгоритмов довольно стандартно: вместо того, чтобы выполнять операцию (в нашем случае enqueue/dequeue) они сначала
объявляют её, — сохраняют дескриптор операции вместе с аргументами в некотором общедоступном разделяемом хранилище, — а затем начинают помогать конкурирующим потокам: просматривают дескрипторы в хранилище и пытаются выполнить то, что в них (дескрипторах) записано. В результате при большой нагрузке несколько потоков выполняют одну и ту же работу, и только один из них будет победителем.
Сложность реализации таких алгоритмов на C++ в основном в том, как реализовать это хранилище и как избавиться от аллокации памяти под дескрипторы.
Библиотека libcds не имеет реализации wait-free очереди. Ибо сами авторы приводят в своем исследовании неутешительные данные о её производительности.
Результаты тестирования
В этой статье я решил изменить своей нелюбви к сравнительным тестам и привести результаты тестирования приведенных выше алгоритмов.
Тесты — синтетические, тестовая машина — двухпроцессорный Debian Linux, Intel Dual Xeon X5670 2.93 GHz, 6 ядер на процессор + hyperthreading, итого 24 логических процессора. На момент проведения тестов машина была практически свободной — idle на уровне 90%.
Компилятор — GCC 4.8.2, оптимизация -O3 -march=native -mtune=native.
Тестируемые очереди — из пространства имен cds::container, то есть не интрузивные. Это значит, что для каждого элемента производится аллокация памяти. Сравнивать будем со стандартными реализациями std::queue<T, std::deque<T>> и std::queue<T, std::list<T>> с синхронизацией мьютексом. Тип T – структура из двух целых. Все lock-free очереди основаны на Hazard Pointer.
Тест на выносливость
Довольно специфический тест. Всего 10 млн enqueue/dequeue пар операций. В первой части тест выполняет 10 млн enqueue, при этом 75% операций — это enqueue, 25% — dequeue (то есть в первой части 10 млн enqueue и 2.5 млн — dequeue). Вторая часть — только dequeue 7.5 млн раз, пока очередь не станет пустой.
Задумка при конструировании этого теста была такой: минимизировать влияние кеша аллокатора, если, конечно, у аллокатора есть кеш.
Абсолютные данные — время выполнения теста:

Что можно сказать? Первое, что бросается в глаза — самой быстрой оказалась
блокируемая std::queue<T, std::deque<T>>. Почему? Думаю, все дело в работе с памятью: std::deque распределяет память блоками по N элементов, а не под каждый элемент. Это наводит на мысль, что в тестах надо напрочь исключить влияние аллокатора, так как он вносит достаточно большие задержки, да к тому же, как правило, имеет внутри себя мьютекс[ы]. Что ж, в libcds есть интрузивные версии всех контейнеров, которые не распределяют память под свои элементы, надо попробовать тест с ними.
Что касается наших lock-free очередей, видно, что все те оптимизации, которые мы рассматривали применительно к MSQueue, дали свои плоды, хотя и не такие уж большие.
Prodcer/consumer test
Вполне себе жизненный тест. Есть N писателей и N читателей очереди. Всего выполняется 10 млн операций записи, соответственно, и 10 млн операций чтения. На графиках число потоков — это сумма числа потоков читателей и писателей.
Абсолютные данные — время выполнения теста:
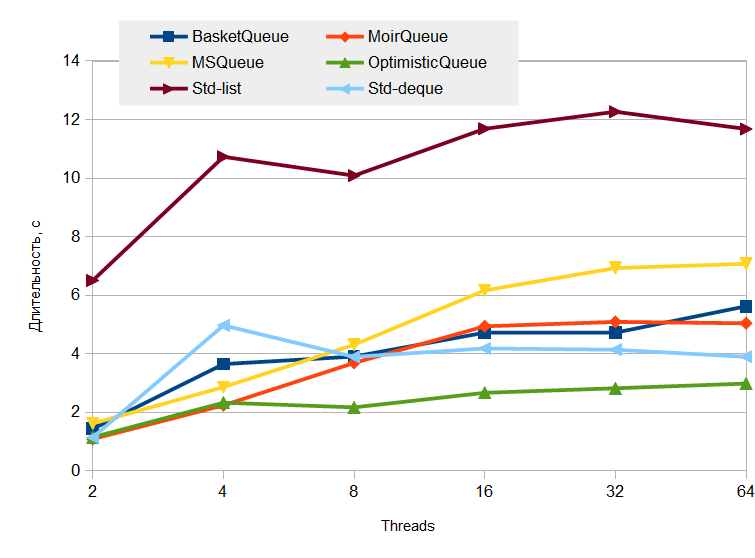
Здесь lock-free очереди ведут себя более достойно. Победителем оказалась OpimisticQueue, — значит, все те допущения, которые были заложены в её конструкцию, себя оправдали.
Этот тест более приближен к реальности, — здесь нет массового накопления элементов в очереди, поэтому в игру вступают внутренние оптимизации аллокатора (я так думаю). Что ж, все правильно, — ведь, в конце концов, очередь предназначена не для безумного накопления, а для буферизации всплесков активности, и нормальное состояние очереди — это отсутствие в ней элементов.
Бонус — к вопросу о стекеРаз уж разговор зашел о тестах…
В перерыве между этой и предыдущей статьей о lock-free стеках я реализовал в libcds elimination back-off для стека Treiber'а. Сама реализация, вернее, путь от описания подхода/псевдокода к законченному продукту на C++ заслуживает отдельной статьи (которая, скорее всего, никогда не будет написана, — слишком много кода пришлось бы в неё вставлять). В результате получилось по сути то, что написано у авторов elimination back-off, но если посмотреть на код — совершенно другое. Пока что доступно только в репозитории libcds.
Здесь же хочу похвастаться привести результаты синтетических тестов. Тестовая машина — та же самая.
Тест — producer/consumer: одни потоки пишут в стек (push), другие — читают (pop). Читателей и писателей — равное число, общее их количество — это число потоков. Общее число элементов — 10 млн (то есть 10 млн push и 10 млн pop). Для стандартных стеков синхронизация осуществляется мьютексом.
Абсолютное время выполнения теста:
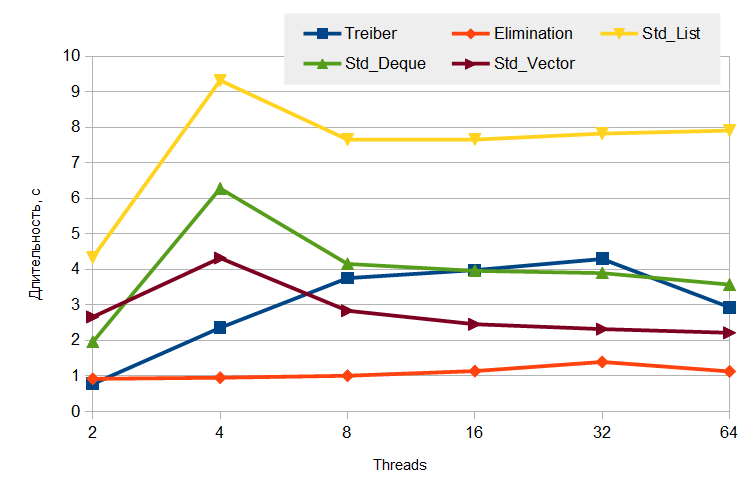
Думаю, график говорит сам за себя.
Интересно, за счет чего достигнут столь высокий рост производительности elimination back-off? Казалось бы, за счет того, что push/pop аннигилируют друг с другом. Но если мы посмотрим на внутреннюю статистику (все классы контейнеров в libcds имеют свою внутреннюю статистику, по умолчанию отключенную), то увидим, что из 10 млн push/pop аннигилировали только 10 – 15 тысяч (в тесте с 64 потоками), то есть около 0.1%, при общем числе попыток (то есть числе входа в elimination back-off) около 35 тысяч! Выходит, что основное достоинство elimination back-off в том, что при обнаружении слишком большой нагрузки некоторые потоки выводятся в спячку (в приведенных результатах сон пассивного потока в elimination back-off длится 5 миллисекунд), тем самым автоматически уменьшая общую нагрузку на стек.
Выводы
Итак, мы рассмотрели классическую lock-free очередь, представленную как список элементов. Такая очередь характеризуется наличием двух точек конкуренции — головы и хвоста. Мы рассмотрели классический алгоритм Майкла и Скотта, а также несколько его улучшений. Надеюсь, что рассмотренные приемы оптимизации были интересны и могут пригодиться в повседневной жизни.
По результатам тестов можно сделать вывод, что, хоть очереди и lock-free, магический CAS не дал какого-то заоблачного выигрыша в производительности. Следовательно, надо искать какие-то другие подходы, позволяющие отказаться от узких мест (головы и хвоста), каким-то образом распараллелить работу с очередью.
Этим мы и займемся в следующем «очередном трактате».
Продолжение следует…
Lock-free структуры данныхНачало
Основы:
Внутри:
Извне:
Автор:
@khizmax
 i-Free Group
i-Free Group
рейтинг
50,29
Компания прекратила активность на сайте














